I work on scaling the reasoning abilities of large language models and LLM agents through search, inference scaling, and reinforcement learning.
I am a Visiting Researcher at Caltech, advised by Yisong Yue. I am pursuing a Ph.D. in Computer Science at Rensselaer Polytechnic Institute, advised by Santiago Paternain and previously by Ziniu Hu, with expected graduation of May 2027. I received my M.S. from the University of Chicago, where I worked with Haifeng Xu and Dacheng Xiu. Before that, I trained as an economist.
My research has been featured in the State of AI Report by Air Street Capital, appearing in the 2024 edition.
- Sep 2025 🎉 One paper accepted to NeurIPS 2025
- Jan 2025 🎉 Two papers accepted to ICLR 2025
- Jan 2025 Joined Caltech as a Visiting Researcher, working with Yisong Yue
- Oct 2024 🎉 One paper accepted at the NeurIPS 2024 Workshop on LanGame
- Jun 2024 🎉 One paper accepted at the ICML 2024 Workshop on AutoRL
- May 2024 Joined NEC Laboratories America as a Research Intern, working with Wei Cheng

Adaptive, compute-aware reasoning - dynamically expands or contracts thought steps for efficient problem-solving. Delivers +33% accuracy vs DeepSeek-R1 at equal tokens and 5-10% lower error on APPS, MATH, and LiveCodeBench.
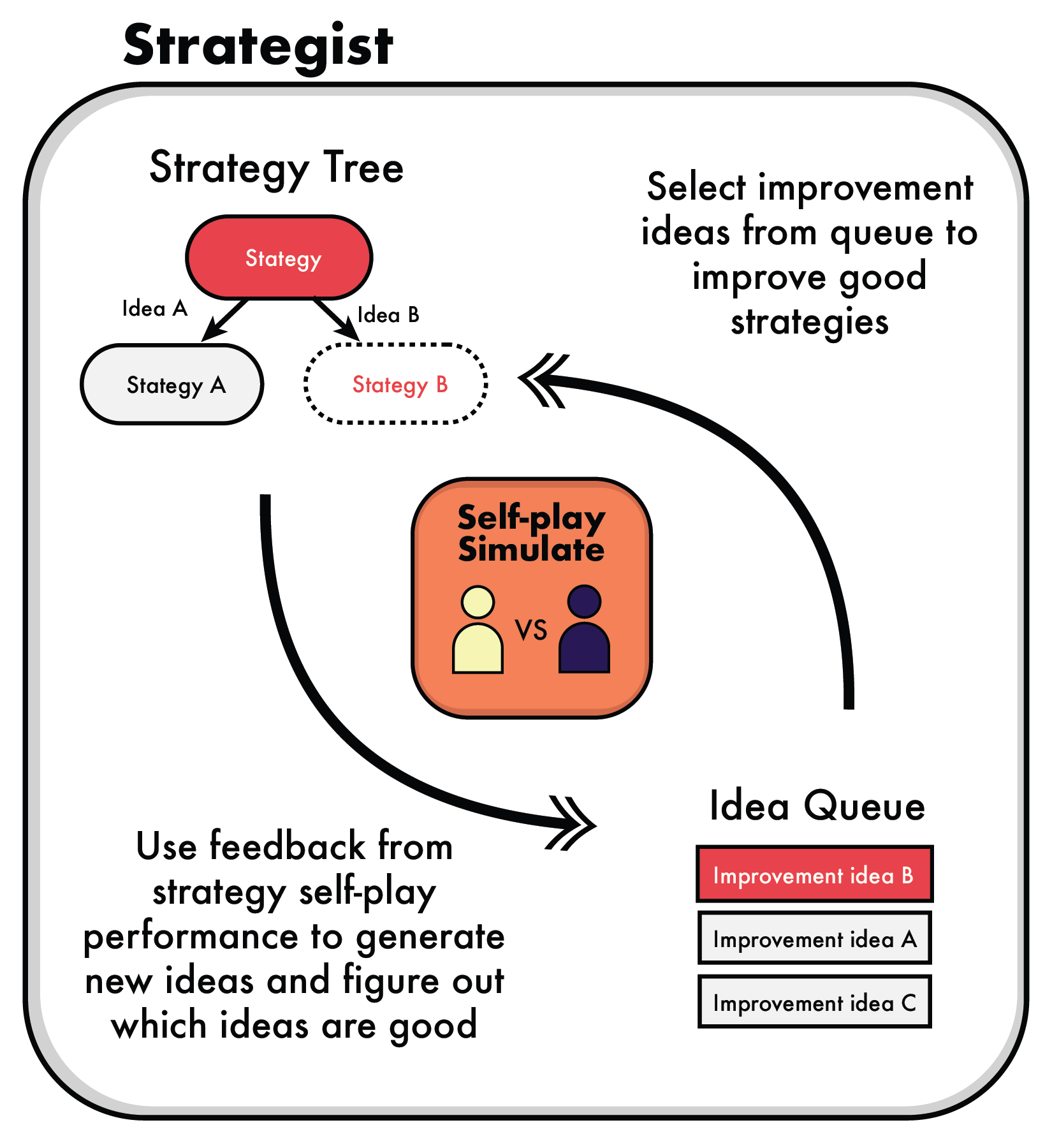
LLM + MCTS hybrid that learns to optimize its own decision process through self-play and strategy refinement. Outperforms RL and existing LLM agents, achieves human-level performance in complex games. Highlighted in the State of AI Report 2024 as a breakthrough in autonomous agent design.
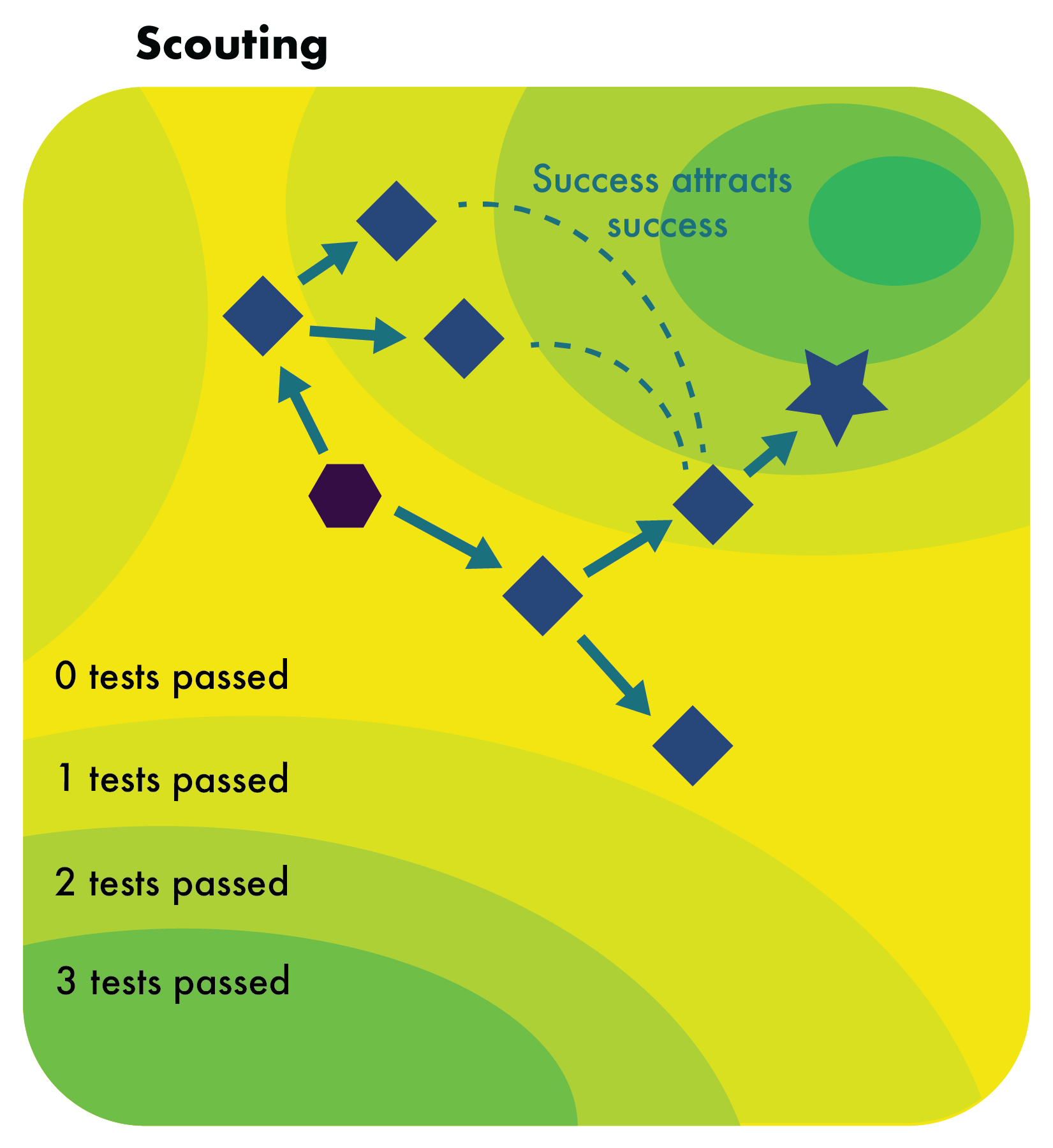
Reframes code generation as black-box optimization: uses Scattering, Foresting, and Scouting to boost exploration + feedback exploitation. Achieves SOTA on HumanEval, MBPP, APPS, CodeContests, LeetCode (e.g. 87.2% pass@1 on HumanEval) while halving iterations vs prior methods.
Ph.D. in Computer Science
Aug 2023 - Present · Rensselaer Polytechnic Institute (RPI), Troy, NYM.S. in Financial Mathematics
Aug 2021 - Mar 2023 · University of Chicago, Chicago, ILB.S. in Mathematics and Economics
Aug 2017 - May 2021 · Reed College, Portland, OR- ICLR Conference Reviewer 2025
- NeurIPS Conference Reviewer 2025
- Phi Beta Kappa 2021
- Reed Commendation for Excellence in Scholarship 2018 · 2019 · 2020 · 2021
- Reed Science Research Fellow 2020
- Reed Financial Services Fellow 2019
- AI and Blockchain Teaching Assistant · Dacheng Xiu · Booth EMBA · 2023 Summer
- Options Pricing Teaching Assistant · Roger Lee · UChicago PSD · 2023 Spring
- Bayesian Statistical Inference and ML Teaching Assistant · Gordan Ritter · UChicago PSD · 2023 Spring
- Decoding Fintech Teaching Assistant · Dacheng Xiu · Booth · 2023 Winter
- Mathematical Statistics Teaching Assistant · Jonathan Wells · Reed College · 2021 Spring
- Probability Theory Teaching Assistant · Jonathan Wells · Reed College · 2020 Fall
- Macroeconomics Teaching Assistant · Zhe (Jasmine) Jiang · Reed College · 2020 Fall
- Econometrics Teaching Assistant · Fellipe Carrera · Reed College · 2020 Fall
- Introduction to Analysis Teaching Assistant · David Krumm · Reed College · 2019 Fall
- MIT CSAIL AI Reasoning at Scale with Search
- Tencent AI Lab Scaling LLM Reasoning through Search and RL
I go by either Jonathan Li or Jonathan Light. I usually use Light in publications because:
- Li is a very common last name. Without exception, every institution I've been to has had at least one other Jonathan Li.
- Light is the semantic translation of my Chinese given name.
- Light nearly preserves the lexigraphic ordering of Li.
I've also considered using "Plum" (the semantic translation of my last name), but it doesn't have the same ring to it, nor does it preserve the lexigraphic ordering of Li. Generally I find semantic translations to be more faithful to the original meaning, as convenient as pinyin is for romanization.