
Adaptive, compute-aware reasoning - dynamically expands or contracts thought steps for efficient problem-solving. Delivers +33% accuracy vs DeepSeek-R1 at equal tokens and 5-10% lower error on APPS, MATH, and LiveCodeBench.
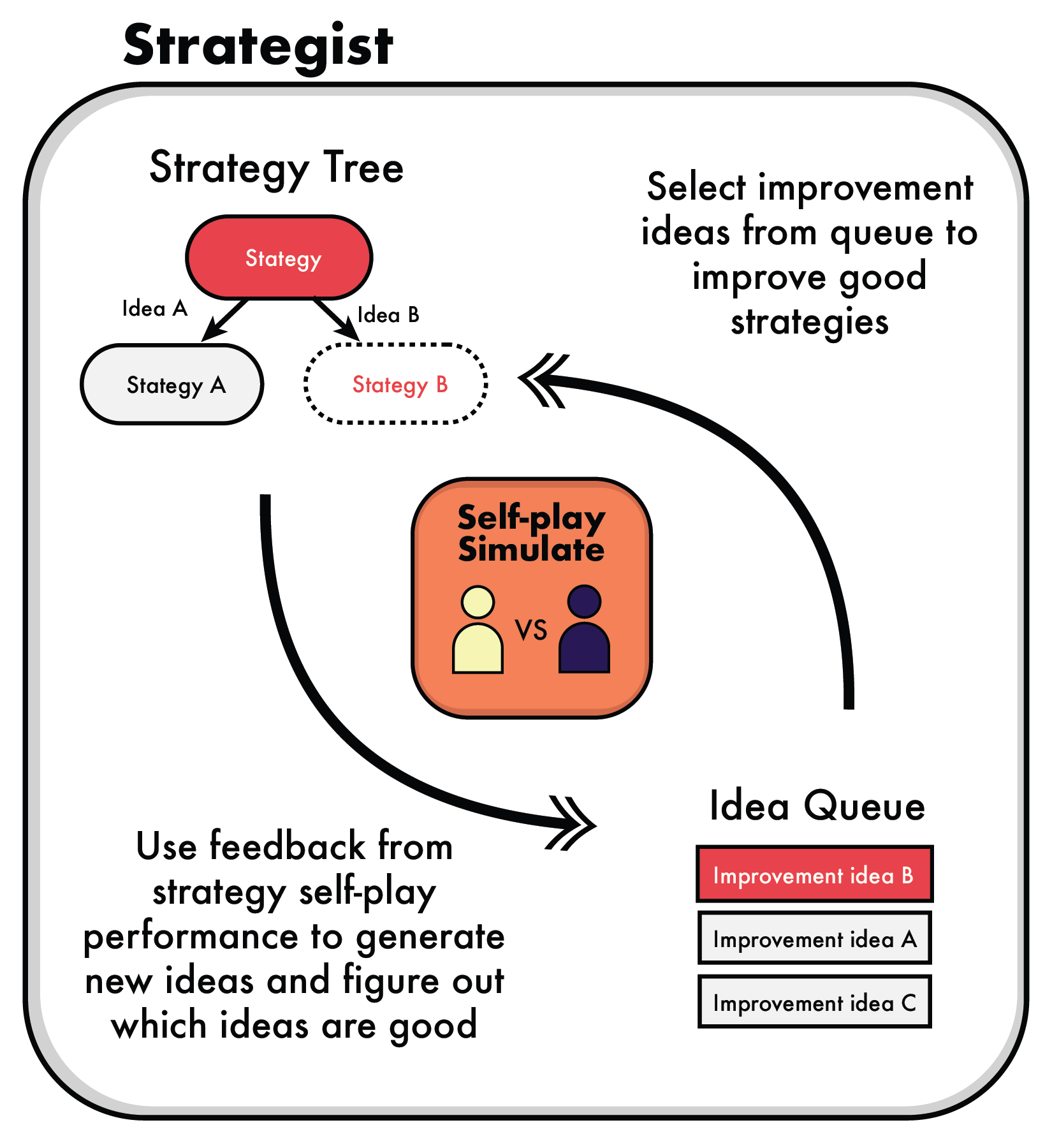
LLM + MCTS hybrid that learns to optimize its own decision process through self-play and strategy refinement. Outperforms RL and existing LLM agents, achieves human-level performance in complex games. Highlighted in the State of AI Report 2024 as a breakthrough in autonomous agent design.
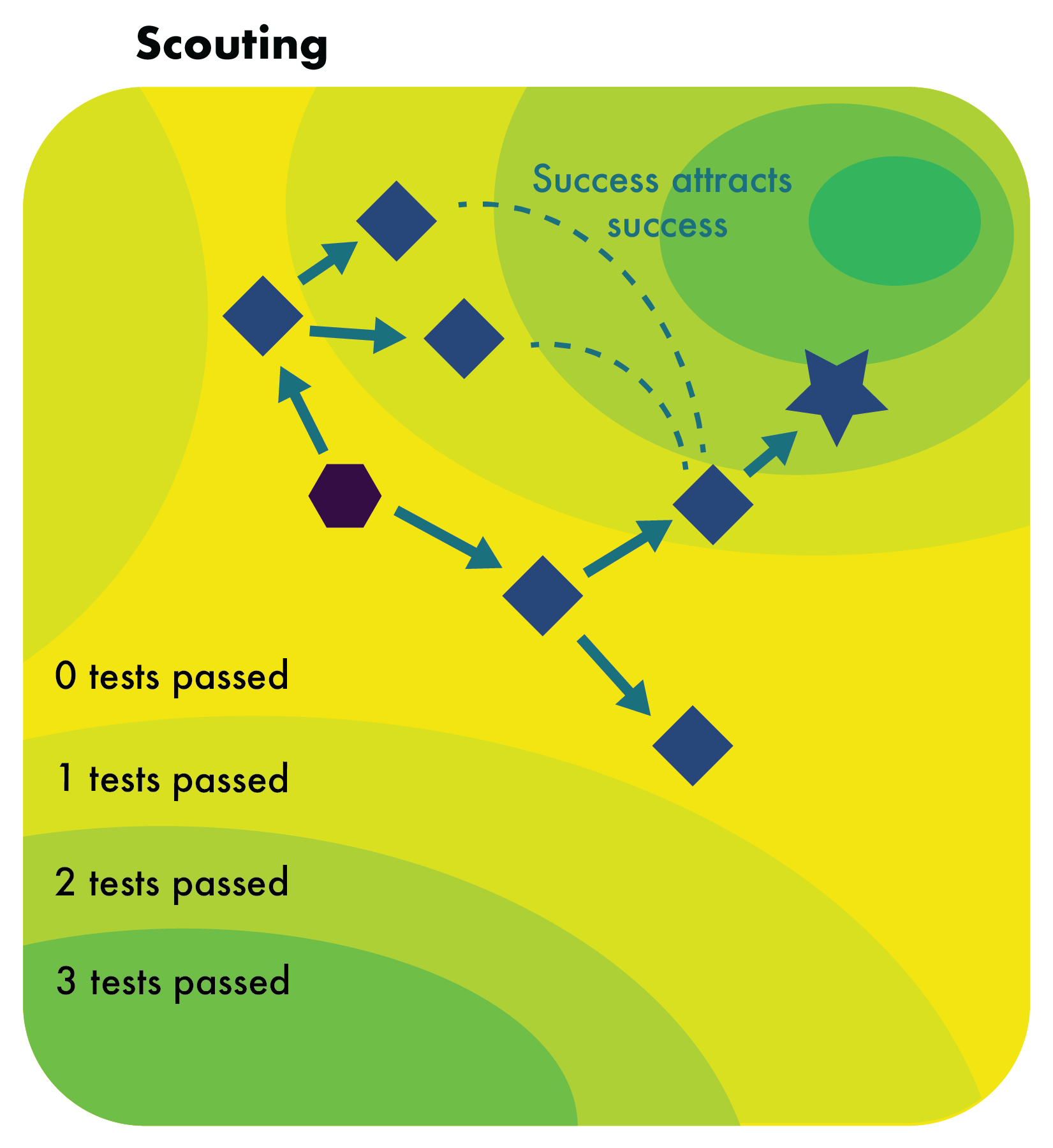
Reframes code generation as black-box optimization: uses Scattering, Foresting, and Scouting to boost exploration + feedback exploitation. Achieves SOTA on HumanEval, MBPP, APPS, CodeContests, LeetCode (e.g. 87.2% pass@1 on HumanEval) while halving iterations vs prior methods.
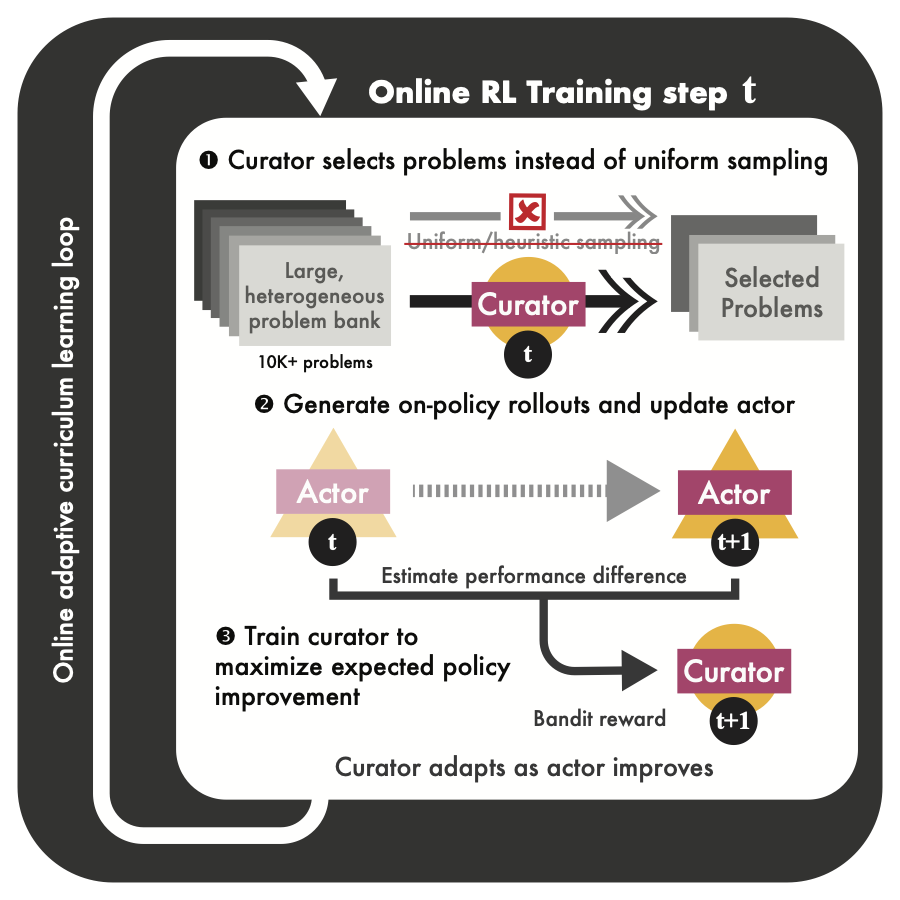
A scalable, fully automated curriculum-learning framework for RL post-training of LLMs. Learns a neural curator that selects training problems to directly maximize expected policy improvement, formulated as a non-stationary bandit with regret guarantees. Delivers +28.6% on AIME2024, +30.5% on ARC-1D, and up to 80% speedup over the strongest baseline.
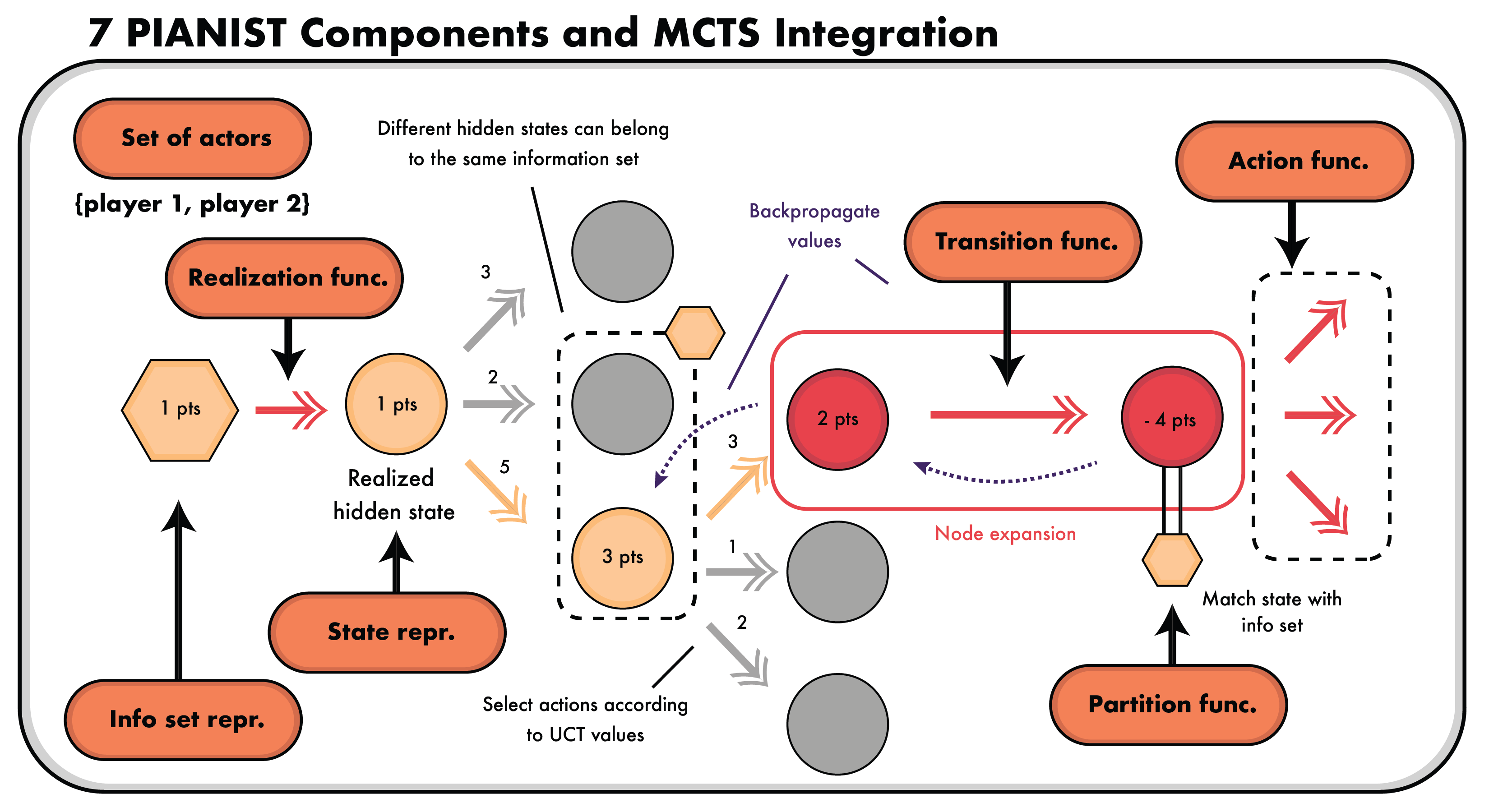
Decomposes language-described environments into intuitive components, enabling zero-shot LLM world models for efficient MCTS in multi-agent settings.
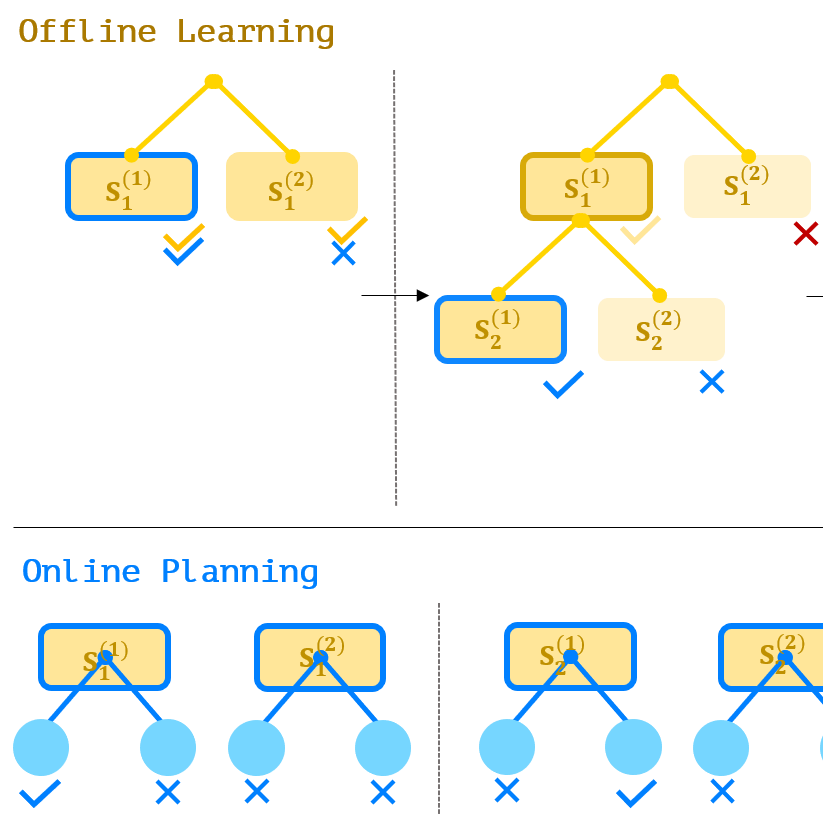
Introduces Reasoning in Reasoning (RiR), a hierarchical planner-actor formulation that unifies decomposition and search to accelerate neural theorem proving across LeanDojo and miniF2F benchmarks.

Introduces AvalonBench to benchmark LLM agents in strategic social deduction games and highlights the gap between current agents and engineered bots.
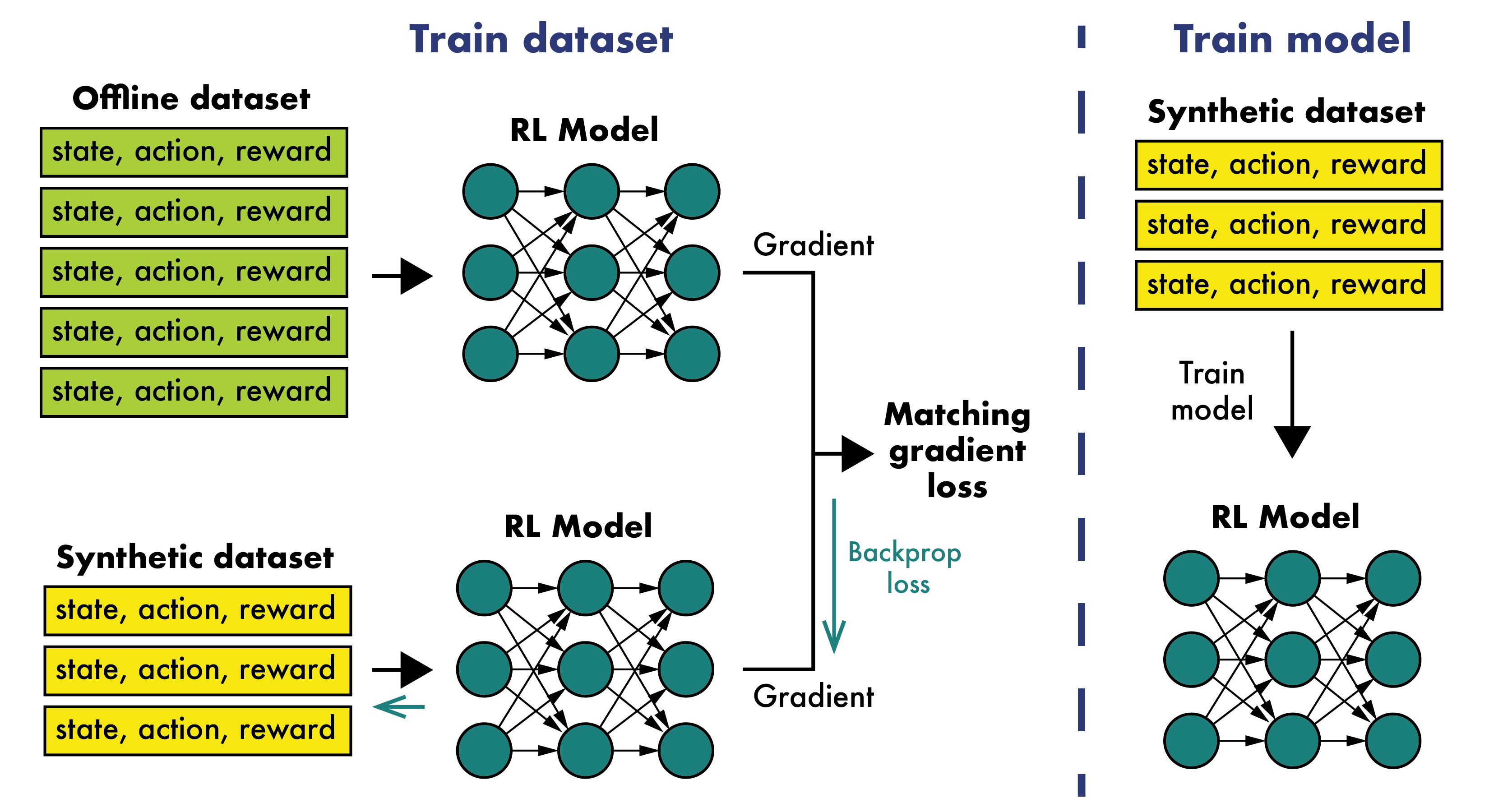
Synthesizes compact, high-quality offline RL datasets that retain policy performance comparable to training on full datasets.